Variable-order Markov model
Variable-order Markov (VOM) models are an important class of models that extend the well known Markov chain models. In contrast to the Markov chain models, where each random variable in a sequence with a Markov property depends on a fixed number of random variables, in VOM models this number of conditioning random variables may vary based on the specific observed realization.
This realization sequence is often called the context; therefore the VOM models are also called context trees [1]. The flexibility in the number of conditioning random variables turns out to be of real advantage for many applications, such as statistical analysis, classification and prediction.[2][3][4]
Contents |
Example
Consider for example a sequence of random variables, each of which takes a value from the ternary alphabet {a, b, c}. Specifically, consider the string aaabcaaabcaaabcaaabc...aaabc constructed from infinite concatenations of the sub-string aaabc.
The VOM model of maximal order 2 can approximate the above string using only the following five conditional probability components: {Pr(a|aa) = 0.5, Pr(b|aa) = 0.5, Pr(c|b) = 1.0, Pr(a|c)= 1.0, Pr(a|ca)= 1.0}.
In this example, Pr(c|ab) = Pr(c|b) = 1.0; therefore, the shorter context b is sufficient to determine the next character. Similarly, the VOM model of maximal order 3 can generate the string exactly using only five conditional probability components, which are all equal to 1.0.
To construct the Markov chain of order 1 for the next character in that string, one must estimate the following 9 conditional probability components: {Pr(a|a), Pr(a|b), Pr(a|c), Pr(b|a), Pr(b|b), Pr(b|c), Pr(c|a), Pr(c|b), Pr(c|c)}. To construct the Markov chain of order 2 for the next character, one must estimate 27 conditional probability components: {Pr(a|aa), Pr(a|ab), ..., Pr(c|cc)}. And to construct the Markov chain of order three for the next character one must estimate the following 81 conditional probability components: {Pr(a|aaa), Pr(a|aab), ..., Pr(c|ccc)}.
In practical settings there is seldom sufficient data to accurately estimate the exponentially increasing number of conditional probability components as the order of the Markov chain increases.
The variable-order Markov model assumes that in realistic settings, there are certain realizations of states (represented by contexts) in which some past states are independent from the future states; accordingly, "a great reduction in the number of model parameters can be achieved."[1]
Definition
Let  be a state space (finite alphabet) of size |A|.
be a state space (finite alphabet) of size |A|.
Consider a sequence with the Markov property 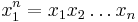 of
of  realizations of random variables, where
realizations of random variables, where 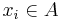 is the state (symbol) at position
is the state (symbol) at position  1≤≤, and the concatenation of states
1≤≤, and the concatenation of states 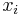 and
and 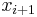 is denoted by
is denoted by 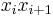 .
.
Given a training set of observed states, 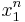 , the construction algorithm of the VOM models[2][3][4] learns a model
, the construction algorithm of the VOM models[2][3][4] learns a model 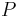 that provides a probability assignment for each state in the sequence given its past (previously observed symbols) or future states.
that provides a probability assignment for each state in the sequence given its past (previously observed symbols) or future states.
Specifically, the learner generates a conditional probability distribution 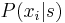 for a symbol given a context
for a symbol given a context 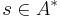 , where the * sign represents a sequence of states of any length, including the empty context.
, where the * sign represents a sequence of states of any length, including the empty context.
VOM models attempt to estimate conditional distributions of the form where the context length |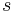 |≤
|≤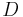 varies depending on the available statistics. In contrast, conventional Markov models attempt to estimate these conditional distributions by assuming a fixed contexts' length ||= and, hence, can be considered as special cases of the VOM models.
varies depending on the available statistics. In contrast, conventional Markov models attempt to estimate these conditional distributions by assuming a fixed contexts' length ||= and, hence, can be considered as special cases of the VOM models.
Effectively, for a given training sequence, the VOM models are found to obtain better model parameterization than the fixed-order Markov models that leads to a better variance-bias tradeoff of the learned models.[2][3][4]
Application areas
Various efficient algorithms have been devised for estimating the parameters of the VOM model.[3]
VOM models have been successfully applied to areas such as machine learning, information theory and bioinformatics, including specific applications such as coding and data compression,[1] document compression,[3] classification and identification of DNA and protein sequences,[2] statistical process control,[4] spam filtering[5] and others.
See also
- Markov chain
- Examples of Markov chains
- Variable order Bayesian network
- Markov process
- Markov chain Monte Carlo
- Semi-Markov process
- Bioinformatics
- Machine learning
- Artificial intelligence
References
- ^ a b c Rissanen, J. (Sep 1983). "A Universal Data Compression System". IEEE Transactions on Information Theory 29 (5): 656–664. doi:10.1109/TIT.1983.1056741. http://ieeexplore.ieee.org/xpl/freeabs_all.jsp?isnumber=22734&arnumber=1056741.
- ^ a b c d Shmilovici, A.; Ben-Gal, I. (2007). "Using a VOM Model for Reconstructing Potential Coding Regions in EST Sequences". Computational Statistics 22 (1): 49–69. doi:10.1007/s00180-007-0021-8. http://www.springerlink.com/content/a447865604519210/.
- ^ a b c d e Begleiter, R.; El-Yaniv, R. and Yona, G. (2004). "On Prediction Using Variable Order Markov models". Journal of Artificial Intelligence Research 22: 385–421. http://www.jair.org/media/1491/live-1491-2335-jair.pdf.
- ^ a b c d Ben-Gal, I.; Morag, G. and Shmilovici, A. (2003). "CSPC: A Monitoring Procedure for State Dependent Processes". Technometrics 45 (4): 293–311. doi:10.1198/004017003000000122. http://www.eng.tau.ac.il/~bengal/Technometrics_final.pdf.
- ^ Bratko, A.; Cormack, G. V., Filipic, B., Lynam, T. and Zupan, B. (2006). "Spam Filtering Using Statistical Data Compression Models". Journal of Machine Learning Research 7: 2673–2698. http://www.jmlr.org/papers/volume7/bratko06a/bratko06a.pdf.